马斯克的五步工作法实践
用马斯克五步工作法拆解并优化 AI Coding 工作流
公司正在推行和实践 AI Coding ,内部有个从开发前产出PRD到开发后测试闭环的工作流,而且这个工作流大而全支持测试、产品、开发、运维、设计这些角色来使用,并用统一的入口来管理,使用也很“优雅”只需要在终端输入启动脚本的别名,就会展开步骤菜单,如下是开发环节的菜单:

使用这套工作流的过程中,你需要根据角色/意图来选择对应的序号,且根据工作流程的推进不断选择序号,在执行到下一个流程之前会根据你给出的上下文来判断是否能进入下个流程,这个过程中会将上下文包装成 prompt 给 coding agent 工具,最后流程选择完毕后会用 CLI 模式启动 Codex 或 Claude Code 来执行任务。这个流程也许是挺好的,可以让不同技术背景,对于 coding agent 有不同理解的人且遵循这套流程的人有稳定和有质量的产出。
简单说,这个中控台做了三件事:
-
用菜单把用户意图路由到固定流程
-
根据流程读取预设上下文和规则
-
把这些内容拼成 prompt,再交给 Codex 或 Claude Code 执行
不过在《埃隆·马斯克传》这本书中马斯克有提到,除了物理定律不可打破之外,一切规则都只是建议,我们要质疑一切需求和流程尤其是聪明人制定的和提出的,因为聪明人页会犯错,而且犯的错更致命、更隐晦。
也许对于那套工作流我们可以用马斯克的理论来拆解并优化一下,如下是马斯克的五步工作法:
-
质疑需求和流程
-
删除不必要的部分
-
精简和优化流程
-
加快迭代速度
-
自动化
质疑需求和流程
首先就要质疑这个流程是否合理,显然让用户记序号,每个流程输入序号这部分不合理,LLM 是有语义理解和意图识别的,但是这个流程把这个过程封装了一层。理想且优雅的方式应该是和 agent 说:“我要生成一个PRD,这个是需求...”,然后 agent 会自己结合用户提供的内容来有目的的阅读代码库,这个期间遇到问题或门禁再反馈给用户或者自己来去寻找问题的解决方案,所以也许我们需要另外一种方式。
删除不必要的部分
记住序号和输入序号的部分实在是不优雅了,应该去掉,不过也可以做得更彻底一点,从一个空的文件夹开始。我的设想是这是一个综合的 workspace,日常的任务直接让 coding agent 在 workspace 根目录下执行,根目录包含了日常开发所涉及的前后端和跨端项目,coding agent 可以根据需求阅读和修改这些项目的代码,将项目聚合在一起减少跨项目开发的摩擦,此时就需要 AGENTS.md 来告诉 agent 这些项目是什么,有什么要注意的,我们不希望每次输入 prompt 之前还要重申上下文。
于是初步的 workspace 就变成:

这是 AGENTS.md 的内容:

现有的中控台中包含了一些上下文和各个模块的开发规范,但是这其中有一些问题,包含但不限于:上下文冲突、用来索引上下文的文件在项目里不一致、上下文噪音太多、大量绝对路径绑定了开发中控台人员的本机路径(这种问题也能出现), 等等。
以下是让 AI 总结的项目目录结构问题(已经缩减过了):
<context-repo>/
├── cc/SKILL.md
│ └── cc 入口规则太重:菜单、路由、报告、门禁、记忆约束都混在一个 skill
├── command/SKILL.md
│ └── 和 cc/SKILL.md 重复维护 1-45 路由、报告格式、门禁规则
├── .ai/commands/
│ └── 每个路由一份 md,但很多规则又被复制到 cc/SKILL.md、command/SKILL.md、harness
├── .ai/harness/
│ ├── route-acceptance-contracts.json
│ ├── routing-rules.md
│ ├── skill-registry.yaml
│ └── memory-governance-policy.md
│ └── 应该是结构化真相源,但现在和 skill 文本、commands 文本并列冲突
├── .ai/skills/
│ └── 子 skill 放在这里,但 registry、cc skill、command skill 都能各自决定怎么调用
├── .ai/memory/
│ └── 有治理结构,但 active/audit 基本空,不能支撑“可信上下文”
└── 记忆库/
├── 索引.md
└── 00-平台通用/、01-租赁管理/...
└── 业务记忆按目录堆放,缺统一 scope/source/trust/audit 元数据
不可否认上下文是有价值的,但整个上下文的组织和编排太混乱了,不利于 coding agent 去读取,这是典型 vibe coding 产物,没有好好的去 review 和测试。
精简和优化流程
那些问题会因为干扰和噪音太多导致执行任务的结果不理想,为了更好的工作流,也许根据具体目的来生成对应的 skill 是个不错的方向,这个 skill 必须是一个完整的、可分发的 bundle。
比如生成 PRD 这个常见的需求,不想在中控台输入序号的话就需要将用到的上下文整合成一个 skill ,现在的 coding agent 应该都默认带了 skill creator 这个 skill ,让 codex 读取 context repo 执行即可,这里不赘述。
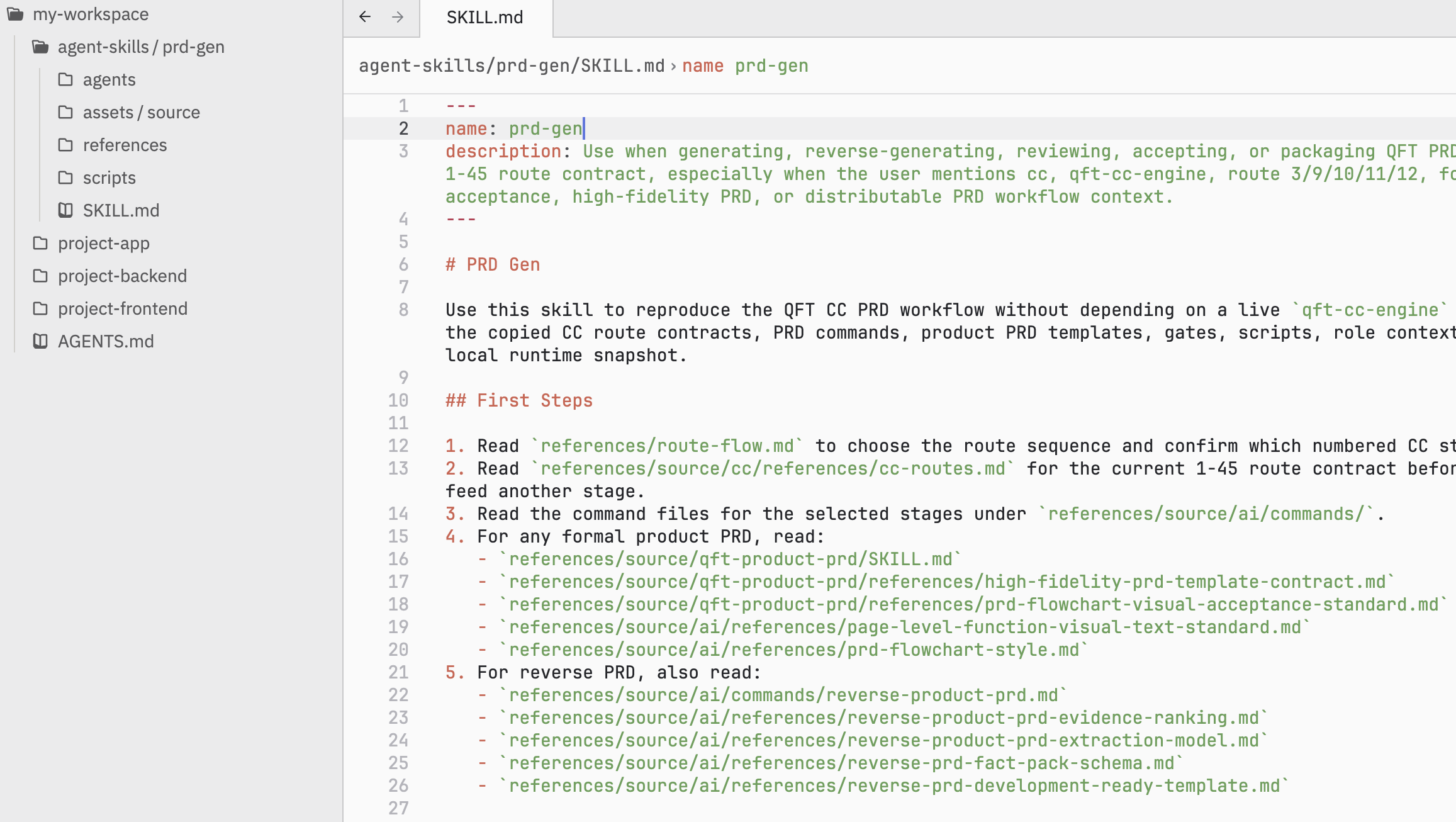
事实上为了不丢失任务上下文,初版的 prd-gen skill 也有噪音和 context 重复的问题,不过这也好解决,让 codex 去精简就行,然后根据使用经验和产生的结果去迭代和逐步完善。
skill 只是一方面,agent 在 coding 的过程中有一些完全不能触犯的原则(尤其是在写后端代码),包括但不限于:SQL语句必须带公司id、注意主表和只读表、写前端要尽可能复用现有的组件、尽可能不修改公共组件等等。
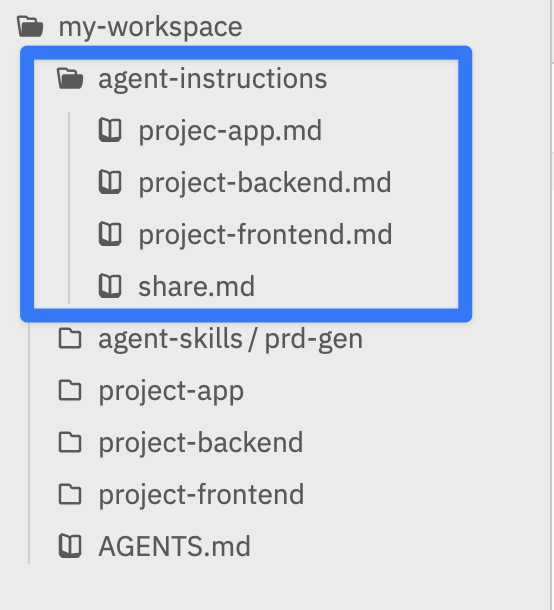
正常情况下应该将这些信息写在各个项目的 AGENTS.md 中,但是我们公司的项目实在有点混乱,每个人对于 agent 的理解还不一样,所以为了不让上下文互相干扰,可以将各个项目的上下文总结在 workspace 中,然后在 workspace 的 AGENTS.md 中告诉 agent 以 agent-instructions/ 中的上下文为准就像这样:
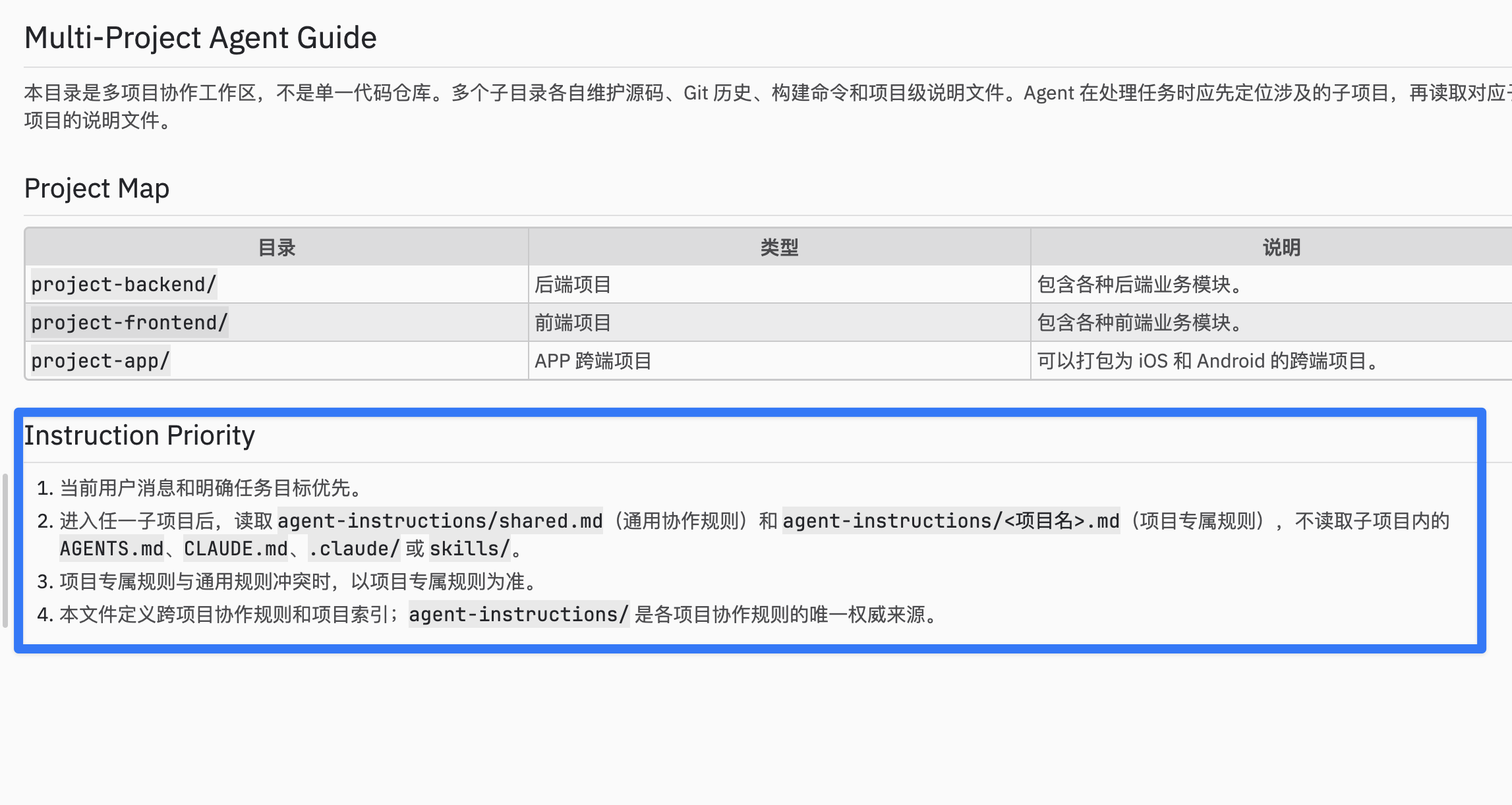
持续迭代
按照剧本这一步应该是加快迭代速度 & 自动化,但是我感觉并不适用于这次的工作流优化没必要强行分为两步,这也算是用马斯克的五步工作法来质疑五步工作法了。
随着不断使用,skill 会变得越来越多,如果你像我一样同时使用多个 coding agent ,但每个 coding agent 读取 skills 的目录不一样,可以设置软链接,这样只需要维护一份 skills:
ln -s ../agent-skills .agents/skills
ln -s ../agent-skills .claude/skills
ln -s ../agent-skills .opencode/skills
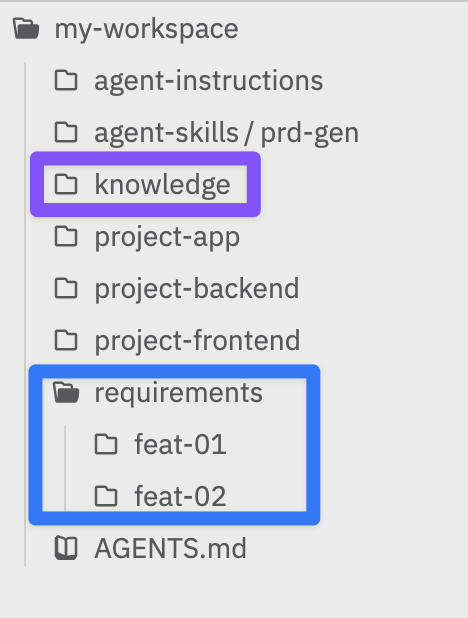
我还有个习惯就是建立 requirements/ 文件夹,将理解后需求整理进这个文件夹,然后手动输入一遍理解的需求文档,这一步会帮你更好的理解需求以及再次确认需求是否合理,然后我会将完成需求过程中一些对于项目的理解沉淀进 knowledge/ 中:
写在最后
我还想吐槽一点,我们公司的这个中控台工作流,居然不让其他的员工去维护上下文,藏着掖着连源码都不让看,但是工作台脚本初始化的过程中又会将完整上下文拉取到用户的本地,想看还是能看到,我也是醉了。
另外这个 workspace 的工作流其实还能优化日常的使用体验,不过具体怎么做,待续...